Thomas Step
I recently launched a Slack app to help with channel bloat. Simply installing it would help me out a bunch. I have 1/10 installations required to submit my app to the Slack Marketplace.
Regular Expression Vulnerability
I stumbled across something interesting the other day that I dove into and wanted to share. There exists a vulnerability called ReDos (Regular expression Denial of Service) which results from a poorly written regular expression taking a long time to complete matching. If an attacker can determine that a regex has been written with this type of vulnerability, they can exploit the long running times to block processes. Since regexes are used for loads of different web services nowadays, I think it is important to understand the time complexities behind regex algorithms and the unintended consequences they could have. I now know that I have written some regexes in the past that are vulnerable, and I know how easy it is to introduce these into code.
One specific variant of ReDos that I came across was catastrophic backtracking. The linked article has more information in it, but the high-level idea is that some regex algorithms that use backtracking to find matches can be given strings that result in exponential time complexity. Anyone who has had a class on discrete math or written an inefficient algorithm, either intentionally or unintentionally, will know that exponential time complexities have a noticeable effect on user experience. That noticeable effect is how attackers can exploit this vulnerability.
Nested quantifiers in regexes are at the root of this problem. Something along the lines of (b+)+z. The + nested inside of a group that is followed by a + sparks the potential for an exponential amount of backtracking attempts. Given a string with repeated bs in it and a z at the end, this regex string would first be greedy and attempt to find a full match after matching all of the repeated bs for the inner nested b+ before it found the final z. At that point, the algorithm would declare a full match and end since it found the final z which would finish the full pattern. If there is no z at the end of the string, we run into our problem. The algorithm will give up the last b for the inner nested b+ and attempt the match again since the b+ is nested inside of a group followed by +. The algorithm is backtracking out of its greediness in hopes that a match can be found. If that still does not work, the algorithm backtracks again and gives up 2 bs. This continues on and on until all of the options are exhausted. This is how the exponential time complexity comes into play.
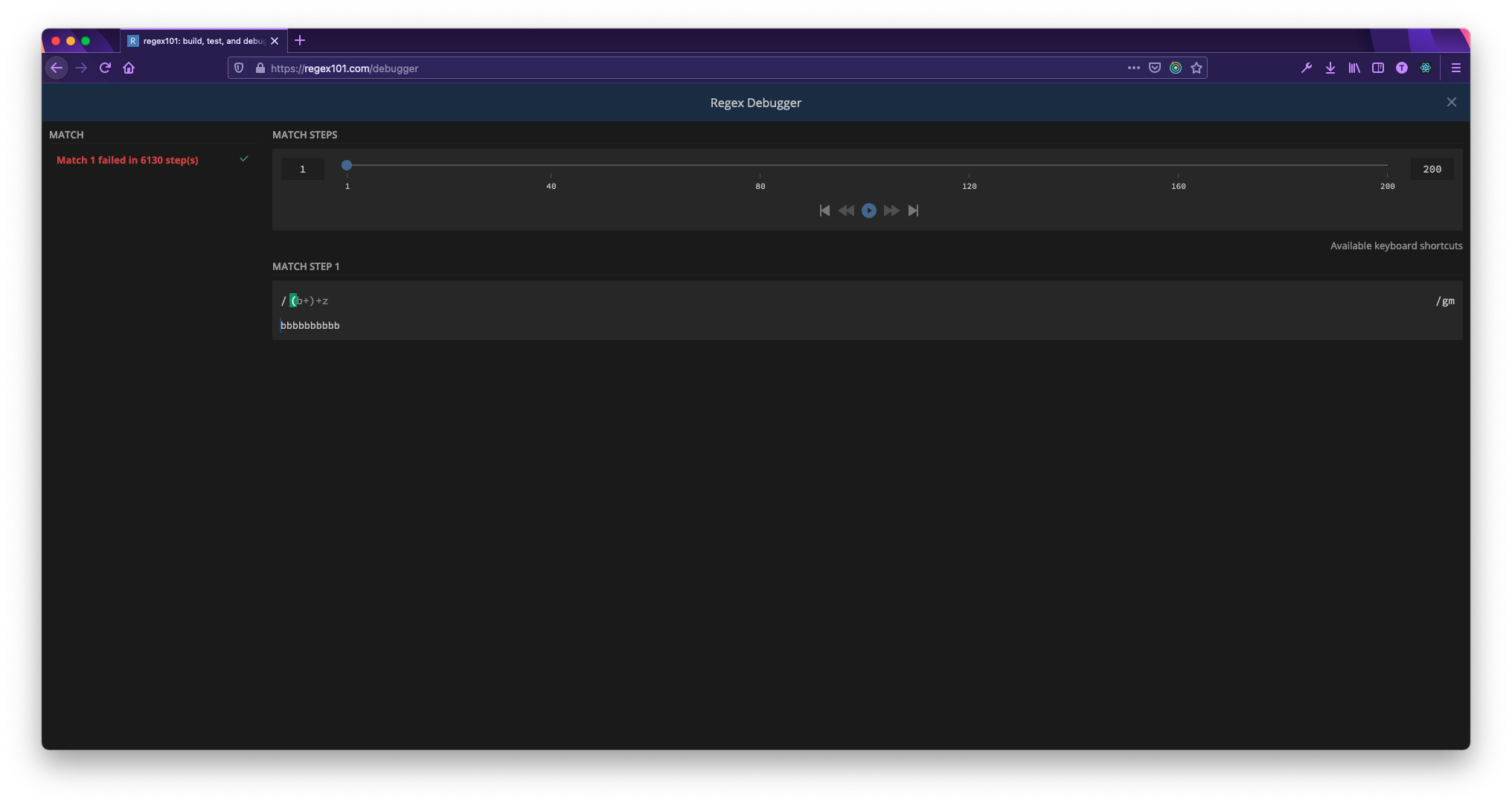
The screenshot above is from regex101.com’s debugger showing what happens when we apply this regex to a string of only bs. No match was found and we can see that there were 6130 steps needed to determine this. To put this into perspective, this regex takes 6 steps to complete and find a match using bbbbbbbbbbz (the same string with a z on the end). Starting from a string consisting of one b and going to ten bs (what is featured in the screenshot above) takes 7, 18, 41, 88, 183, 374, 757, 1524, 3059, 6130 steps, respectively. We can already start to see the exponential increase just from n = 1 to n = 10.
To help mitigate this, one quick and simple method is to apply atomic groups to the nested repetition: (?>b+)+z. Testing this from one to ten bs looks like 7, 12, 17, 22, 27, 32, 37, 42, 47, 52 steps, respectively. These results show a linear time complexity, which is much better. The atomic grouping operator (?>) is explicitly telling the engine not to backtrack. We can do this because we know there is no way the algorithm could find a z if it just matched all bs. This is only one example of a problematic regex and a solution though. Other patterns need to be considered as well, and I suggest reading through this page and this page to learn more about them.
This is all fine and dandy, but how does it apply to me? Well, have you ever told a regex to “match anything”? The notorious .*. I bet most people who have written a regex know what that is and have used it. I know I have. The problem with .* combined with the greediness of most regex engines is that it will most likely match an entire string before backtracking to match with the rest of the regex. If a .*, or any other quantifier, somehow slips in next to another quantifier, a vulnerability might have been introduced. The reasoning for this is the same as the earlier (b+)+z example. Backtracking issues can also stem from nested quantifiers or ORs that can match the same text. While some known patterns unveil potentially problematic regexes, developers need to at least know about this time complexity whenever regexes are brought up.
Higher time complexities in regexes can affect the end-user experience in any application that matches, filters, routes, or sorts. Applications that utilize regexes and handle heavy traffic or process data streams come to mind. An unoptimized regex could bring about unintended backtracking even if it does not introduce a known ReDos pattern. Those extra backtracking steps could start to be felt as extra latency by end-users if a service is under heavy load, and any developer who has dealt with high scaling systems knows that added latency is a major downside. Data streaming is particularly interesting in this aspect. Services like AWS Kinesis, Fluentd, or Fluent Bit could take too long to parse or match data streaming through them, which could end up causing backups or traffic jams. Fluent Bit even has a warning about ReDoS in their documentation.
After hearing about this, I would imagine that it’s fairly uncommon; however, this has happened to both Cloudflare and StackOverflow fairly recently, which are considered solid engineering teams. Problems seem to stem from regexes that are added to or created without thinking about strings that don’t match. It can be difficult to make regexes match in the first place, so developers don’t have time to think about what could go wrong after implementing them. In cases like this fuzz testing might be able to help catch slow regexes. Also, the cryptic-looking nature of regexes doesn’t invite debugging or the desire to walk through the algorithms that live behind the scenes. On top of all that, I hadn’t even heard of this before a few days ago when I stumbled across mentions of it. After reading up on ReDos, my new approach while creating regexes will be to use a debugging program like regex101.com where I can walk through the steps needed to match a string and see what happens if that string doesn’t match.
I have not seen too many posts that explicitly highlight this vulnerability, but it is only fair that I mention this article that also helped me understand what was going on behind the scenes. While I believe there are other, more pressing issues that developers need to worry about, I also believe that we should all at least know that this problem exists. Whenever a regex needs to be used, I plan on referencing this vulnerability before writing anything to make sure that I don’t introduce unnecessary latency or the vulnerability itself.
Categories: dev | security